Сегодня заметка будет посвящена теме далекой от веб-программирования, она будет посвящена немного алгоритмам, немного парсингу и немного Mongodb. Будем сегодня играть в игру.
Часто по вечерам мы с женой играем в приложение на iPad’е под названием Словомания.

Смысл в нем, как вы, наверное, заметили из названия, поиск слов. На входе матрица 4х4, можно начать из любой клетки и задействовать соседние по одному разу, чтобы отыскать имеющееся у них в словаре слово (в том словаре есть и наречия, и глаголы, и прилагательные, и конечно же существительные).
Задача: отыскать все слова. Но я немного облегчу себе задачу, потому как по примерным подсчетам в матрице 4х4 всевозможных комбинаций поиска слова около 16 миллионов, что даже по скромным подсчетам и при словаре в ~160 тысяч слов займет около 5 часов. В данной заметке мы будем использовать матрицу 3х3, что сокращает количество комбинаций до 8 с небольшим тысяч, что вполне приемлимо, но недостаточно быстро, для одной игры, которая длится около минуты. Да и плевать, для меня главное решить задачу, хоть и читерить в игре не получится ).
Для начала отыщем все возможные комбинации, для этого воспользуемся php-скриптом поиска в ширину, немного его изменив для наших нужд. На выходе должны получить файл, где в каждой строке одна комбинация.
Цифры на матрице я обозначил от 1 до 9 (3х3), поэтому в выходном файле будут строки подобного вида – 1,2,3,6,5,4,7,8,9.
Но сначала нам пригодится небольшой скрипт, который поможет построить граф для таблицы 3х3.
1 2 3 4 | |
На выходе получим таблицу
1 2 3 | |
которая поможет нам построить граф, ключами массива которого будут вершины “откуда”, значениями – точки “куда”, мы можем попасть из данной вершины. Из таблицы следует, что из точки 1, мы можем попасть в точки: 2,5 (по диагонали тоже можно) и 4. Так нам нужно описать каждую вершину графа.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
В коде старался комментировать каждый момент, поэтому, думаю, должно быть понятно. На выходе у нас файлы combinations.dat с 8175 строками из всевозможных комбинаций.
Теперь давайте подготовим наш словарь. Я скачал какой-то орфографический словарь, каждая строка которого предствляла собой следующее жопа#жопа %жопа, -ы
Я решил сохранить два первых слова, точнее слово и ударение (которое в данном проекте не используется). Первое слово отделено от второго #, второе от остального %. По мере парсинга словаря, мы будем записывать все слова в нашу mongo базу данных для быстрого поиска по ней в дальнейшем.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Если вам лень запускать подобный скрипт, то в корне проекта лежит файл words.json, содержащий все слова, вы можете импортировать его в свою mongo базу командой mongoimport -d DB -c COLLECTION words.json.
Далее, чтобы ускорить и без того медленное приложение, нужно создать индекс в базе на поле word, запускаем mongo-терминал, выбираем базу данных use DB и пишем следующее
db.COLLECTION.ensureIndex({word: 1}), где DB – имя ваше базы данных, а COLLECTION – имя коллекции.
Итак, переходим к завершающей части – моменту истины, так сказать, поиску слов.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | |
После этого запускаем скрипт ruby find-words.rb, откидываемся на спинку стула и ждем результат. Начнут появляться на экране слова, которые были найдены этим скриптом, возможны повторения, потому что одно слово может быть составлено из разных комбинаций.
Удачи в кодинге и побольше интересных задач, которые вам под силу решить :).
P.S.: репозиторий, как всегда, доступен на github.
update 25.03.2012 Все-таки намного интереснее заставить приложение работать как задумывалось, а именно, чтобы оно находило слова из матрицы 4х4. Для этого мною были предприняты следующие меры:
- удаление лишних слов из словаря
- оптимизация самого алгоритма
- сужение диапазона поиска
Удаление лишних слов из словаря
Пробежался я по словарю и понял, что там много слово, содержащих дефисы, скобки, пробелы. Некоторые слова состояли из одной-двух букв. Я решил с ними попрощаться, благо mongo поддерживает регулярные выражения.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Запускаем и удаляем ненужные слова, из 160 тысяч слов, останется 140 тысяч, неплохо :)
Оптимизация самого алгоритма
Самый быстрый код – это мало кода. Поэтому максимально постараемся избавиться от методов. Выбросив все лишнее получим следующее.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
Код получился намного “легче” и быстрее.
Сужаем диапазон поиска
Чтобы хоть как-то еще прибавить скорость, я сузил длину слова, теперь проверяются только строки от 3 до 9 символов, это тоже очень хорошо сужает конечную выборку.
Обратная связь приветствуется
Если вы видите, что есть какие-то неточности или гипотезы по поводу оптимизации быстродействия кода, то всегда пожалуйста, я открыт для обсуждения всегда.
Не хочу быть излишне самоуверенным, но мне, кажется, что сейчас весь алгоритм упирается в “железо”, точнее скорость считывания с диска. (К сожалению, у меня нет ssd диска, чтобы это проверить).
В заключение картинка с какой скоростью отрабатывает скрипт. Первое число на картинке – количество секунд на 100_000 строк, считанных из файла и проверенных с каждой строкой словаря, содержащего ~ 140.000 слов. Второе число – сколько строк уже просмотрено. Всего комбинаций получилось, если рассматривать поле 4х4 – 12.000.000 штук. :)
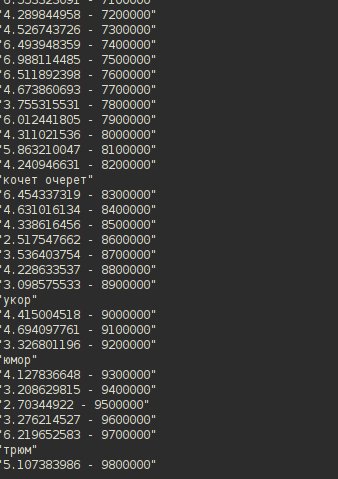
Обновление от 27.03.2012 (redis)
Пришла еще одна мысля по оптимизации данного приложения, вместо mongodb, я решил попробовать использовать redis – очень быстрое ключ-значение хранилище.
Сначала нужно экспортировать базу mongo в redis, тут ничего сложного (с учетом того, что у вас и сам redis установлен, и redis gem).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Пробегаемся по всем словам из коллекции mongodb и сохраняем все слова в redis под ключом word:СЛОВО, чтобы не перепутать с другими ключами.
Теперь основной файл, только в качестве хранилища мы будем использовать redis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
Вывод: приложение стало заметно быстрее (в 3-5 раз), скриншот прилагаю.
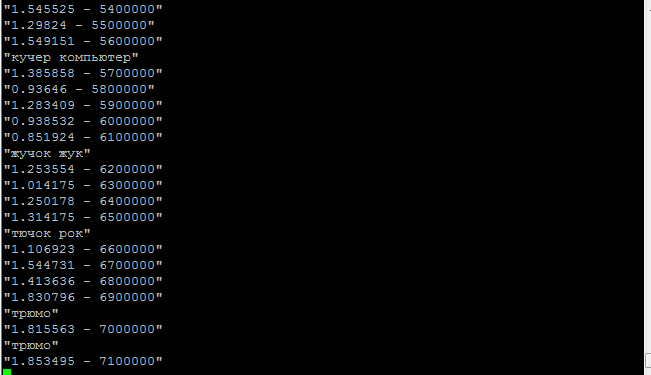
Надеюсь, смогу добиться скорость выполнения в раза больше, чем сейчас. Мне нужно чтобы приложение проходило по всем комбинациям, сравнивая со всем словами в словаре и тратило при этом меньше минуты, сейчас около 3х.